Objective
The objective of this tutorial is to make you understand – what is SAP Process Integration? We will not go into the nitty-gritty of the subject but we will discuss about the architecture and different features of SAP PI. We will cover the basic features only and will avoid discussing all features in this tutorial.
Next there are a set of case studies which will give you an idea about the industry level utilization of SAP PI. Once you get more acquainted with the subject, you should try to solve them. The test cases are prepared in a manner so that it will take you down into the subject from simple to more complexes with each lesson and will give you an overall idea of the subject.
What is SAP ERP?
For any business – large or small, these are the standard business functionalities it must carry out i.e. Material Management, Sales and Distribution, Finance, Human Resources etc. There is much software in the market which is utilized by the industry. You will notice the simplest one – the teller machine generating sales invoice if you visit a small shop to a network of computers in a large retail store, hotel etc operating on an ERP.
Enterprise Resource Planning i.e. ERP is an effective approach that most businesses implement to enhance their productivity and performance. SAP ERP is SAP AG’s Enterprise Resource Planning, an integrated software solution that incorporates the key business functions of the organization. The basic functionalities i.e. HR, MM, SD, FICO etc are called business modules in SAP. SAP builds them as products and sells them in the market. There are two more modules which do not support business functions directly but are utilized for presentation and integration. The former is called EP (Enterprise Portal) and the latter is called PI (Process Integration). All the business modules are developed in ABAP while EP and PI are developed mostly in Java. These modules are not executables but they need to be deployed in an Application Server i.e. ABAP Web Application Server for ABAP modules and Java Web Application Servers for Java modules.
There are few points we should know before we jump into the subject.
- SAP stands for Systems, Applications, and Products in Data Processing.
- SAP AG is a German multinational software corporation that makes enterprise software to manage business operations and customer relations. SAP ERP is the corporation’s Enterprise Resource Planning, an integrated software solution that incorporates the key business functions of the organization.
- SAP NetWeaver Process Integration (SAP PI) is SAP enterprise application integration (EAI) software, a component of the NetWeaver product group used to facilitate the exchange of information among a company’s internal software and systems and those of external parties.
Legacy System
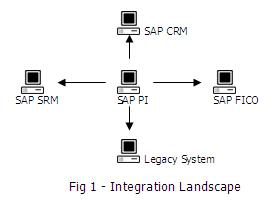
While implementing the SAP ERP in a large business establishment, it is found that not all sections can be brought under the SAP ERP. Many of the business sections may have their own proprietary tools which are highly complex and may not be possible to be replaced. They run parallel to the SAP System. They are called the Legacy Systems. Then it becomes necessary to integrate between the SAP Systems and such pre-existing non-SAP System. This is where the SAP PI comes into play.
Why do we need SAP PI 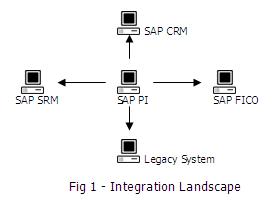
Apart from Legacy Systems, in a large business establishment, SAP ERP does not consist of a single system but several integrated systems i.e. CRM, SRM and FICO etc. To handle with such complexities SAP introduced Process Integration a platform to provide a single point of integration for all systems without touching existing complex network of legacy systems. This is a powerful middleware by SAP to provide seamless end to end integration between SAP and non-SAP applications inside and outside the corporate boundary. SAP PI supports B2B as well as A2A exchanges, supports synchronous and asynchronous message exchange and includes built in engine for designing and executing Integration Processes.
Architecture of SAP PI
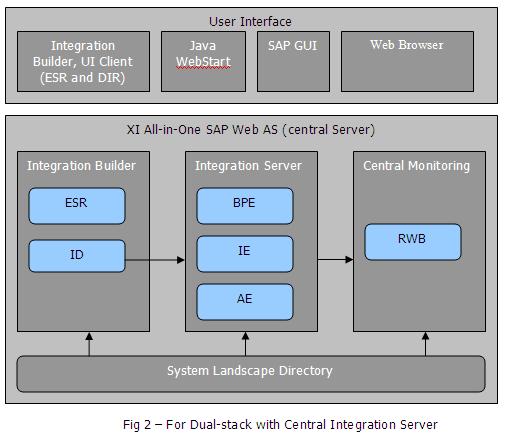
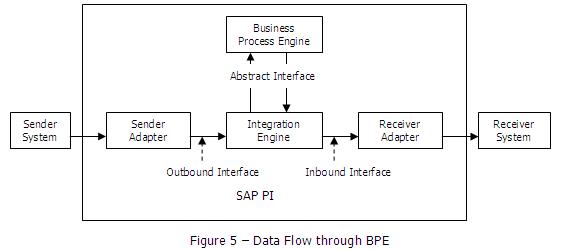
The SAP PI consists of a hub and spoke structure; the spokes connect with external systems while the hub exchange messages between them. The source system is known as the sender system and the target system is known as the receiver system. The PI is not a single component, but rather a collection of components that work together flexibly to implement integration scenarios. The architecture includes components to be used at design time, at configuration time and at run time.
We can divide the SAP PI into several areas
- Integration Server
- Integration Builder
- System Landscape
- Configuration and Monitoring
Integration Server is the central processing engine of the SAP PI. All messages are processed here in a consistent way. It consists of three separate engines
- Integration Engine
- Adapter Engine
- Business Process Engine
Integration engine can be considered to be the hub and the Adapter engine the spoke. Regarding the Business Process Engine, I will explain it later.
Integration Builder is a client-server framework for accessing and editing integration objects and it consists of two related tools:
- Enterprise Service Repository – to design and develop objects to be used in scenarios
- Integration Directory – to configure the ESR objects to develop scenarios
Two together, we built integration processes which are commonly called scenarios.
The System Landscape is a central repository of information about software and systems in data center and simplifies the administration of your system landscape.
In Configuration and Monitoring we can monitor the messages and adapters.
Single stack and Dual stack
When PI was first released, not all components were built on the same platform. Integration Engine and Business Process Engine was built in ABAP while Adapter Engine, Integration Builder, SL, CM and Mapping Runtime were built in Java. So PI needs both the Java and the ABAP environment to run and is known as the dual stack.
|
ABAP Stack |
Java Stack |
|
|
But in the later version all the components are built in Java. Some of the dual-stack components are either dispensed off or modified to work on the Java stack. So PI needs only the Java environment to run and is known as the single stack.
There are pros and cons between the two stacks but they are not covered in this tutorial.
Integration Engine
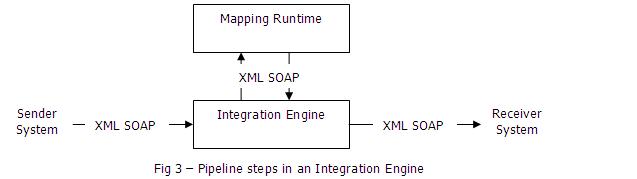
The Integration Engine is responsible for central Integration Server services i.e. the pipe-line steps – routing and mapping. If the source message structure is different from the target message structure, then integration engine calls the Mapping Runtime, where source structure is converted to the target structure. The Mapping Runtime is based on the Java stack. The integration engine can also utilize an ABAP program for the conversion, which is based on the ABAP stack.
A message can be of two types
- Synchronous – has both the request-response part
- Asynchronous – has either the request or the response part only
In PI, message is represented by an interface.
Interface -> structure of the message in XML format + direction
Based on the above criteria, there are three types of interfaces
- Outbound interface – connect to the sender system
- Inbound interface – connect to the receiver system
- Abstract interface – connect to the BPE
When we configure integration logic (scenario) in the SAP PI as per our business requirements, it is the integration engine which executes that configuration in a step-wise manner. Pipeline is the term used to refer to all steps that are performed during the processing of an XML message. The pipe-line steps consist of the following:
- Receiver Identification – determines the system that participates in the exchange of the message.
- Interface Determination – determine which interface will should receive the message.
- Message Split – if more than one receiver are found, PI will instantiate new message for each receiver.
- Message Mapping – mapping to transform the source message to destination message format.
- Technical Routing – bind a specific destination and protocol to the message.
- Call Adapter – send the transformed message to the adapter or a proxy.
Adapter Engine
You must have noticed earlier that the integration engine handles messages in XML-SOAP protocol only. But what if we have a sender and a receiver business system where the data is not in the same format. We use the various adapters in the Adapter Engine to convert XML- and HTTP-based messages to the specific protocol and format required by these systems, and vice versa.

As we have discussed earlier, SAP PI is a hub and spoke structure where the Adapter Engine can be considered as spoke. We use the Adapter Engine to connect the Integration Engine (Hub) to the external systems. The Adapter Framework is the basis of the Adapter Engine. The Adapter Framework is based on the SAP J2EE Engine (as part of the SAP Web Application Server) and the J2EE Connector Architecture (JCA). The Adapter Framework provides interfaces for configuration, management, and monitoring of adapters.
In a dual stack system, most of the adapters where based on the Java stack barring two adapters which are based on the ABAP stack.
| Java Stack | RFC adapter, SAP Business Connector adapter, file/FTP adapter, JDBC adapter, JMS adapter, SOAP adapter, Marketplace Adapter, Mail adapter, RNIF adapter, CIDX adapter |
| ABAP stack | IDOC adapter and HTTP adapter |
When SAP PI moved from dual stack to single stack then these two adapters became part of the Java stack. The modified adapter engine is known as the Advance Adapter Engine and the two adapters are called the IDOC_AAE adapter and HTTP_AAE adapter respectively.
Business Process Engine
The Business Process Engine is responsible for executing and persisting integration processes.
BPM stands for cross-component Business Process Management or ccBPM and is also called Integration process. An integration process is an executable, cross-system process for processing messages. In an integration process you define all the process steps that are to be executed and the parameters relevant for controlling the process. Business Process Management provides SAP Exchange Infrastructure with the following functions:
- State-full message processing: The status of an integration process is persisted on the Integration Server.
- You can also use correlations to establish semantic relationships between messages.
- You implement integration processes when you want to define, control, and monitor complex integration processes that extend across enterprise and application boundaries i.e. collect/Merge, Split, Multicast
At runtime, the Business Process Engine executes the integration processes. The integration process can send and receive messages using abstract interfaces only.
Build a scenario in SAP PI
We start from the Home page if we have to build a scenario in PI.
The home page will look similar to as given below:
Figure 6 – Home Page for SAP PI Java Stack
The Home page has hyperlinks to the following 4 working areas
- Enterprise Services Repository (ESR)
- Integration Directory (ID)
- System Landscape (SL)
- Configuration and Monitoring (CM)
Each hyperlink will open one application. All these four are Java application. ESR and ID are swing applications. They are launched from the browser based on JNLP. So for the first time it takes more time as it downloads the entire library file. But from second time onwards, it takes less time to launch. SL and CM are pure web applications and run on the browser.
Enterprise Services Repository
Here we design and create objects to be used in the making of an integration scenario. The data flow in PI will look similar to as shown below:

We find the option to design the following
- Interface objects – Service Interface, Message Type, Data Type
- Mapping objects – Operation Mapping and Message Mapping
- Integration Processes

PI uses integration repository to design message structure for both sender and receiver systems and develop an interface message using corresponding message structures which act as a point of interaction to the outside world. Data type and Message type are used to simplify and modularize the design of a complex interface.

Operation Mapping allows transformation of source structure to target structure when the two structures are different. But if the source and the target structure are same then the operation mapping may be dispensed off. Similar to service interface, message mapping is used to simplify and modularize the design of a complex operation mapping. Message mapping can be implemented in 4 ways
- Graphical Mapping
- Java Mapping
- XSLT Mapping
- ABAP Mapping
Graphical mapping is the most used as it allows developer to map attributes of both structures graphically to pass data using service interfaces. For the other three, we have to develop the mapping by writing code. If it is a single stack server, then the ABAP mapping will not be available.
There are other areas also, but they are not covered in this tutorial.
Integration Directory
Here we make the pipe-line steps by configuring the ESR objects created earlier. These steps are executed by the integration engine during run-time.
Before we start the configuration we need to create/import the following objects in the DIR.
- Service – Business System/ Business Service/ Integration Process
- Communication Channel
A service enables you to address a sender or receiver of messages. Depending on how you want to use the service, you can select from the following service types.
- Business System – If you want to address a particular business system as the sender or receiver of messages, choose this service type. A business system is an actual application system in a system landscape.
- Business Service – If you want to address an abstract business entity as the sender or receiver of messages, choose this service type. A business service is not defined in the system landscape.
- Integration Process Service – If you want to address an integration process as the sender or receiver of messages, choose this service type. At runtime, these integration processes are controlled by messages and can themselves send messages.
Communication channel determines the inbound and outbound processing of messages. The messages are converted from native format to soap-xml specific message format and vice-versa through the adapter. Generally there are two types of communication channel in a scenario
- Sender Communication channel
- Receiver Communication channel
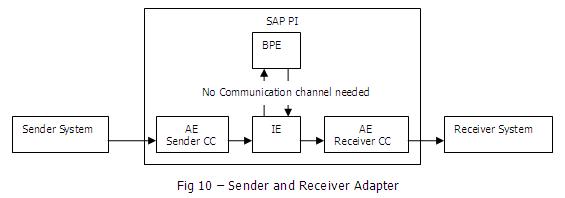
You must assign a communication channel to a service. Depending on whether the service is addressed as a sender or receiver of messages, the assigned communication channel has the role of either a sender or a receiver channel, and must be configured accordingly. You cannot assign a communication channel to an integration process service.
The pipe-line steps are created by creating the following 4 configuration in the DIR
We find the following options:
- Sender Agreement
- Receiver Determination
- Interface Determination
- Receiver Agreement
Sender agreement defines how the message of a sender is to be transformed so that it can be processed by the Integration Server. It consists of the following
- Sender Component
- Sender Interface
- Sender Communication Channel
Sender Agreement is similar to primary key in table. There cannot be the two similar sender agreements in one landscape.
Receiver Agreement defines how the message is to be transformed so that it can be processed by a receiver. It consists of
- Sender Component
- Receiver Component
- Receiver Interface
- Receiver Communication channel
You use a receiver determination to specify which receivers a message is to be sent to. You have the option of defining conditions for forwarding the message to the receivers. It consists of
- Sender Component
- Sender Interface
- Receiver Component
Receiver Determination is of two types – Standard or Extended, depending upon whether you want to specify the Receiver manually or dynamically by a mapping at runtime.
You use an interface determination to specify which inbound interface of a receiver; the message is to be forwarded to. You can also specify which interface mapping from the Integration Repository is to be used for processing the message i.e. if the sender and the receiver interface are not of the same format then there is an operational mapping to change the format. You define an interface determination for a sender, an outbound interface, and a receiver. It consists of
- Sender Component
- Sender Interface
- Receiver Component
- Receiver Interface
Interface Determination is of two types – Standard or Enhanced, depending upon whether you want to specify the receiver interface manually or through mapping-based message split.
Receiver Determination and Interface Determination – the two together are commonly known as the logical routing. Sender Agreement and Receiver Agreement – the two together are commonly known as the Collaboration Agreement.
System Landscape
The SAP System Landscape Directory (SLD) is the central information provider in a system landscape. In the web page you will find the following links:
- Technical System – Technical systems are application systems that are installed in your system landscape.
- Business System – Business systems are logical systems, which function as senders or receivers within PI. Business Systems has one-to-one dependency with the associated technical system.
- Products and Components – This is information about all available SAP products and components, including their versions. If there are any third-party products in the system landscape, they are also registered here.
The SLD will look similar to as given below:
Figure 11 – System Landscape
Products and Components are commonly called the Component Information
Technical System and Business System are commonly called the Landscape Description.
A business system can be configured as an Integration server or Application system.
- Integration Server – The Integration server executes only integration logic configured in the Integration Builder. They can also be identified as Pipe Line Steps. It receives XML message, determines the receiver, executes the mappings, and routes the XML message to the corresponding receiver systems. Thus configured Integration Engine is identified to be Central Configured Integration engine.
- Application system – The Application system will not execute the integration logic. It in turn calls the integration server to execute the integration logic if required. It acts as sender or receiver of XML messages. So, the Application system with a local Integration Engine requires the Integration server to execute the integration logic.
Only one client of SAP system can be configured as Integration Server.

The following information are extracted from the SLD into the ESR and DIR
- Component Information are used in the ESR to define the Product and the SWCV
- Business System are used in the Directory for defining the sender and receiver of messages
Configuration and Monitoring
It is the central entry point for monitoring purposes. This gives you the option of navigating to the monitoring functions of the Integration Engine, as well as integration with the Computing Center Management System (CCMS), and the Process Monitoring Infrastructure (PMI) of SAP.
The Configuration and Monitoring will look similar to as given below:
Figure 13 – Configuration and Monitoring
With the Configuration and Monitoring the following monitoring functions are supported:
- Component monitoring – monitoring the different SAP PI components (Java and ABAP parts).
- Message monitoring – tracking the message processing status within an SAP PI component and on error detection and analysis.
- End-to-end monitoring – monitoring of a message lifecycle from the SAP PI point of view.
- Performance monitoring – statistics about different performance aspects of SAP PI can be accessed through the RWB. Here, you can select and aggregate performance data, for example, by component, time range, or message attributes.
- Index administration – by administering and monitoring the indexing of messages per SAP PI component, you enable an index-based message search that you can use in message monitoring. This kind of message search offers you enhanced selection criteria including adapter-specific message attributes and terms or phrases from the message payload.
- Alert configuration – by using the Alert Framework, central monitoring in PI can be provided with all errors reported during message processing in ABAP and Java. This enables an improved reaction to such errors in both the ABAP runtime and the Java-based Adapter Engine. For this purpose, the Alert Framework is provided with rules based on certain events and on information from the header of the PI message protocol. These rules determine whether alerts are send or not. If an alert is sent, it can be used for error analysis.
- Alert inbox – the alert inbox is user-specific and displays all the alerts for each alert server that has been generated based on the alert configuration.
- Cache monitoring – cache monitoring displays objects that are currently in the runtime cache. Different cache objects are monitored depending on the cache instance concerned.
Synchronous vs. Asynchronous communication
A process can be defined as either synchronous or asynchronous.
- A synchronous process is invoked by a request/response operation, and the result of the process is returned to the caller immediately via this operation.
- An asynchronous process is invoked by a one-way operation and the result and any faults are returned by invoking other one-way operations. The result is returned to the caller via a callback operation.
In the computer world, there is no asynchronous communication. All communication between two systems is always via method call (request/response operation). So how do we make it asynchronous? The answer lies with the introduction of a third system in between the called and the caller function.
Suppose there are two systems – A and B. All communication between A and B is via a method call and thus they are synchronous. We introduce a third system between A and B and called it the Intermediate system – I. The communication between A and I is via method call and similarly between I and B is also via method call. But the communication between A and B can be called asynchronous as A does not have to wait for the response from B.

This is the basis of asynchronous communication and what is this intermediate system? That is the Queue. A is called the sender and B is called the receiver. Message from A is first added to the Queue and then it is again pulled from the Queue and send to B. The response from B reaches A in a similar fashion. In certain situation, the business requirement needs the messages to be delivered to B in the same order as they are triggered from A. In such case we follow a first-in and first-out policy. If there are no such requirements then messages are sending from the queue to B in any order.
With asynchronous communication, we achieve guaranteed delivery i.e. System B is not available when System A sends the message. The message is added to the queue and remains there as long as B is not available. Once B is available, the message is pulled from the queue and sends to B.
So we can classify our message communication in three ways:
- Synchronous
- Asynchronous with order not maintained
- Asynchronous with order maintained
In PI, we identify them as: Synchronous – BE (Best Effort), Asynchronous with order not maintained – EO (Exactly Once), Asynchronous with order maintained – EOIO (Exactly Once in Order).
Acknowledgment
Acknowledgment is the root of asynchronous communication. Why?
For synchronous communication, System A calls system B and if B fails to send the response the process failed. But in an asynchronous communication, System A calls System I and System I calls System B. So suppose the communication between A and I is successful but between I and B, it fails. How should A realize that the delivery to B has failed? This is realized by an acknowledgment which is send back to A by B via the same route as the message from A took to B. If the acknowledgment from B fails to arrive to A then A consider that the process has failed and will send the message again.

While we discussed about asynchronous communication in PI, we have used the term – ‘Exactly Once’ for both EO and EOIO. Exactly Once means a message delivered once cannot be delivered again. To achieve this, there is an acknowledgment for every message send from A to B. It is the adapters which lie at the end of the communication. So the adapters must support acknowledgment.
All adapters’ provide system-acknowledgment i.e. delivery acknowledgment. Those adapters which support synchronous communication support application-acknowledgment in addition to the system acknowledgment.
So in PI, following are the type of acknowledgment
- System Acknowledgment – System acknowledgments used by the runtime environment to confirm that an asynchronous message has reached the receiver.
- Application Acknowledgment – Application acknowledgments used to confirm that the asynchronous message has been successfully processed at the receiver.
Remote Function Call
While working in PI, you will come across the term – RFC. What are they? To establish communication between two SAP systems i.e. an R/3 and PI, we create the RFC Destination. It is configured by the following
- Connection Type
- IP Address and Port of the receiver
Connection Type tells the type of System Connection i.e. R/3, TCP/IP, Internal etc.
The RFC Destination we create is classified according to the mode of communication required i.e. whether it should support synchronous or asynchronous communication.
- for synchronous communication – Synchronous RFC
- for asynchronous communication with order not maintained – Transactional RFC
- for asynchronous communication with order maintained – Queued RFC
They are identified by sRFC, tRFC and qRFC.
Case Studies – 1
Assume that you are in a class room and there are 10 students in it. The instructor then asks each student to prepare his/her the following personal details and save them in an XML file. The details are as follows:
- Student ID
- Name
- Mobile
- Gender
There will be 10 files and the files are named as cv_1,2,3….10. The files are saved into the source directory. For test purposes following directories are created:
Source directory: c:\ibm\sap\training\input
Archive directory: c:\ibm\sap\training\archive
Error directory: c:\ibm\sap\training\error
Target directory: c:\ibm\sap\training\target
You are asked to develop scenarios in SAP PI which will read the source files from the source directory and write them to the target directory. Once a file is successfully read from the source directory, it should be moved to the archive directory and if the file cannot be read for some error i.e. xml format not maintained, it should be moved to the error directory. The files moved to archive, error or target directory should have a time-stamp append to the file-name.
- i.e. filename+<time-stamp>.
Lesson-1
Prepare a scenario to read one single file i.e. file cv_1.xml from the source directory and write it to the target directory. The target file name should also be cv_1.xml with the time-stamp append to the name.
Lesson-2
Prepare a scenario to read all the files from the source directory and write them to the target directory. Similarly the target files should also be named as cv_1, 2 ..xml with the time-stamp append to each of them.
Lesson-3
The instructor then asks you all to add the following validation to the data.
-
-
- The mobile-number should have 10 numeric digits – if the mobile number is not of 10 digit then replace it with ‘error’
- The email should have one ‘@’ character and one ‘.’ character – if the email is not having the ‘@’ or ‘.’ character, then replace it with ‘error’
-
Before you run the scenario, in some of the source files, modify the mobile and the email so that they are in error as per the logic given above.
Lesson-4
Prepare a scenario to read all the source files and classify them according to their gender. The files for the men will be written in one directory and for the ladies to another directory. Two directories are created for the above purpose:
Target directory for men: c:\ibm\sap\training\target\men
Target directory for women: c:\ibm\sap\training\target\women
Suppose there are 6 men and 4 women in the class, then if all the source files are read successfully then the target directory for men should have 6 files and the target directory for women should have 4 files.
Case Studies – 2
The instructor then asks you all to prepare one single file with the personal details of each student in separate segments.
Lesson-5
Write a scenario which will read this file and produces 10 target files where each file should correspond to the personal data of each employee. The target files should be named as cv_<emp_ID>_<timestamp>
Lesson-6
Modify the above scenario so that it produces 2 target files instead of 10 where one target file for men and another target file for the ladies. The target file for men should have 6 segments for 6 men and the target file for ladies should have 4 segments for 4 women.
The target files should be named as
For men – men_<time-stamp>
For Ladies – women_<time_stamp>
Case Study -3
Same as case study – 1, the instructor ask each student to prepare his/her the personal details and save them in an XML file. There will be 10 files. The files are saved in the source directory.
Lesson-7
Prepare a scenario to read all the source files from the source directory and to create one single file in the target directory. The name of the target file will be output.xml with the time stamp append to the file-name. The target file will have all the details of each source file as sub-segment.
Lesson-8
Prepare a scenario to read the entire source files from the source directory and create two files in the target directory – one for the men and the other for the ladies. For 6 men, the men file should have six segments having each man’s details and for 4 women, similarly there should be 4 segments with each lady’s details.
Case Study – 4
The instructor now asks each of the students to prepare another set of details which will consist of his/her the following academic details:
- Student ID
- School Name
- College Name
- Department Name
- Admission Year
There will be 10 files and the files are named as ad_1, 2, 3….10. The files are saved into the source directory. So each student will now have a pair of files – one for the personal details and the other for the academic details. Two files are co-related with the Student ID. The input directory now consists of 10 personal files and 10 academic files.
Lesson – 9
You are asked to develop a scenario which will pick the source files and will process them in pair. The scenario will generate 10 target files. Each target file will consist of the personal and academic details of a student in separate segments. The target files will be named as res_1, 2, 10.
The target files will look like:
Lesson – 10
You are then asked to change the student ID in some of the files so that they do not have a matching academic or personal files and vice-versa. The scenario should run and if it found any files who does not have a matching corresponding file then the process should end after some period of time i.e. 2 min and those files will be moved to the error directory and there will be no corresponding target files for them.
Leave A Comment?
You must be logged in to post a comment.